publications
-
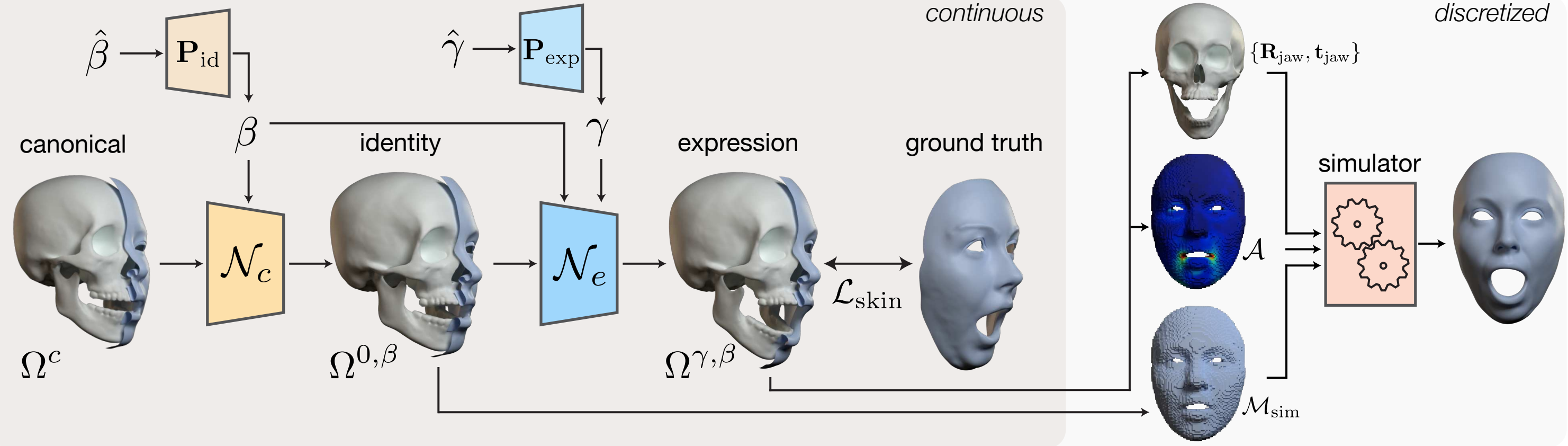
 Learning a Generalized Physical Face Model From DataLingchen Yang, Gaspard Zoss , Prashanth Chandran , and 4 more authorsACM Transactions on Graphics (SIGGRAPH) 2024.
Learning a Generalized Physical Face Model From DataLingchen Yang, Gaspard Zoss , Prashanth Chandran , and 4 more authorsACM Transactions on Graphics (SIGGRAPH) 2024.Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today’s methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
-
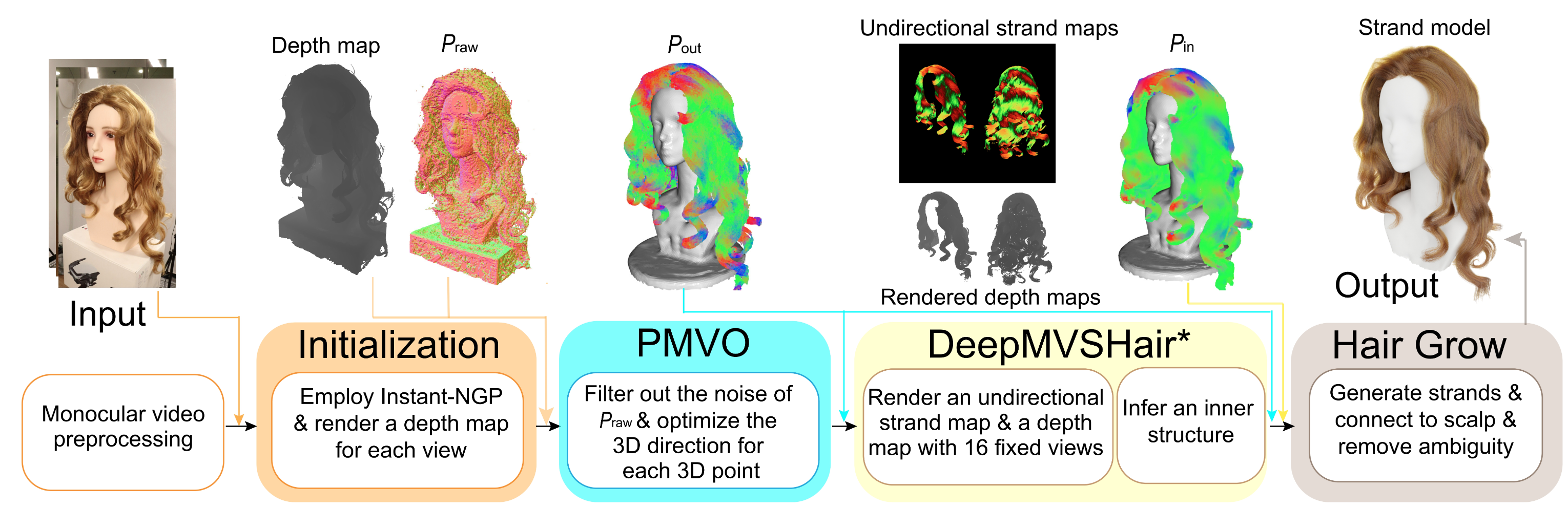
 MonoHair: High-Fidelity Hair Modeling from a Monocular VideoKeyu Wu , Lingchen Yang, Zhiyi Kuang , and 6 more authorsConference on Computer Vision and Pattern Recognition (CVPR) 2024. (Oral 3.3%)
MonoHair: High-Fidelity Hair Modeling from a Monocular VideoKeyu Wu , Lingchen Yang, Zhiyi Kuang , and 6 more authorsConference on Computer Vision and Pattern Recognition (CVPR) 2024. (Oral 3.3%)Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair, a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization. This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair’s inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance.
-
 Efficient Incremental Potential Contact for Actuated Face SimulationLingchen Yang, Bo Li , and Barbara SolenthalerSIGGRAPH Asia Technical Communications 2023.
Efficient Incremental Potential Contact for Actuated Face SimulationLingchen Yang, Bo Li , and Barbara SolenthalerSIGGRAPH Asia Technical Communications 2023.We present a quasi-static finite element simulator for human face animation. We model the face as an actuated soft body, which can be efficiently simulated using Projective Dynamics (PD). We adopt Incremental Potential Contact (IPC) to handle self-intersection. However, directly integrating IPC into the simulation would impede the high efficiency of the PD solver, since the stiffness matrix in the global step is no longer constant and cannot be pre-factorized. We notice that the actual number of vertices affected by the collision is only a small fraction of the whole model, and by utilizing this fact we effectively decrease the scale of the linear system to be solved. With the proposed optimization method for collision, we achieve high visual fidelity at a relatively low performance overhead.
-
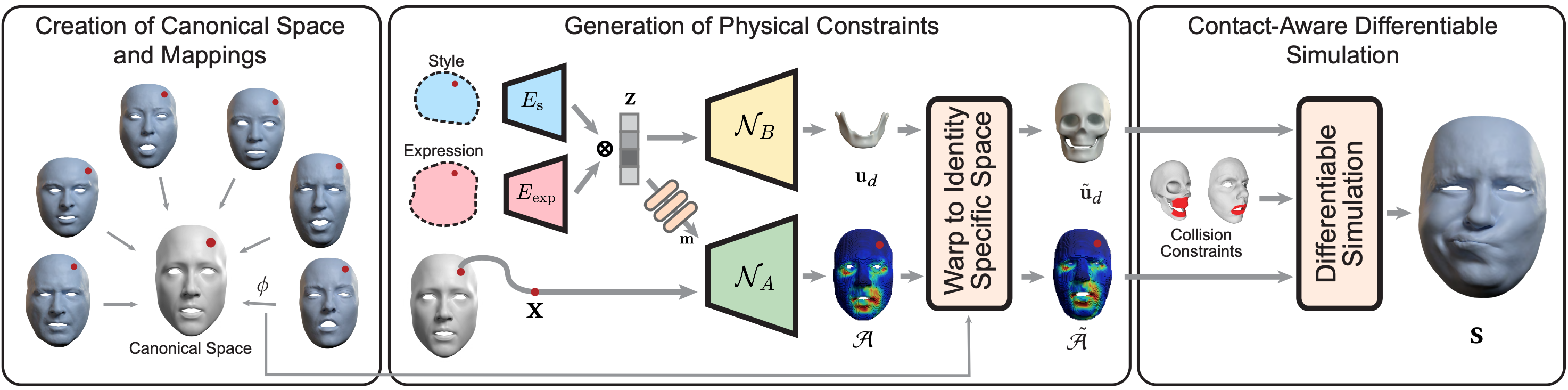
 An Implicit Physical Face Model Driven by Expression and StyleLingchen Yang, Gaspard Zoss , Prashanth Chandran , and 5 more authorsSIGGRAPH ASIA 2023.
An Implicit Physical Face Model Driven by Expression and StyleLingchen Yang, Gaspard Zoss , Prashanth Chandran , and 5 more authorsSIGGRAPH ASIA 2023.3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression ’style’, as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
-
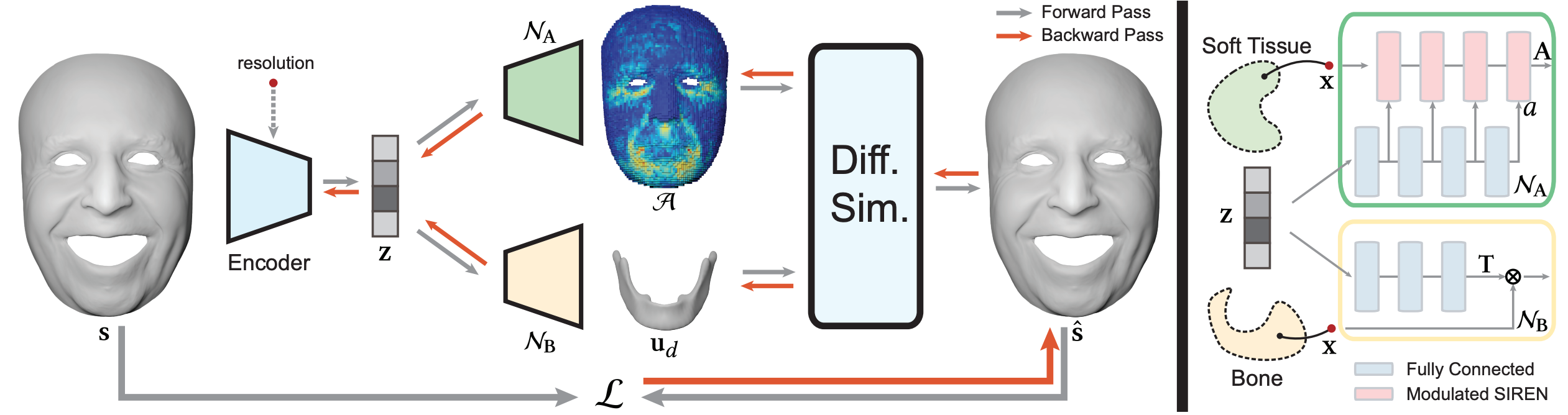
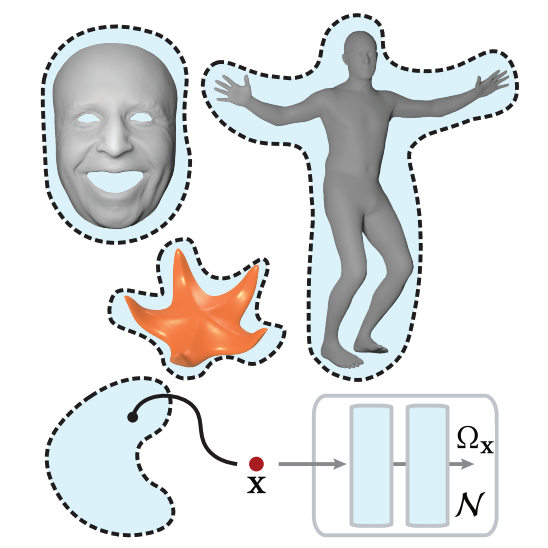 Implicit Neural Representation for Physics-driven Actuated Soft BodiesLingchen Yang, Byungsoo Kim , Gaspard Zoss , and 3 more authorsACM Transactions on Graphics (SIGGRAPH) 2022. (Honorable Mention)
Implicit Neural Representation for Physics-driven Actuated Soft BodiesLingchen Yang, Byungsoo Kim , Gaspard Zoss , and 3 more authorsACM Transactions on Graphics (SIGGRAPH) 2022. (Honorable Mention)Active soft bodies can affect their shape through an internal actuation mechanism that induces a deformation. Similar to recent work, this paper utilizes a differentiable, quasi-static, and physics-based simulation layer to optimize for actuation signals parameterized by neural networks. Our key contribution is a general and implicit formulation to control active soft bodies by defining a function that enables a continuous mapping from a spatial point in the material space to the actuation value. This property allows us to capture the signal’s dominant frequencies, making the method discretization agnostic and widely applicable. We extend our implicit model to mandible kinematics for the particular case of facial animation and show that we can reliably reproduce facial expressions captured with high-quality capture systems. We apply the method to volumetric soft bodies, human poses, and facial expressions, demonstrating artist-friendly properties, such as simple control over the latent space and resolution invariance at test time.
-
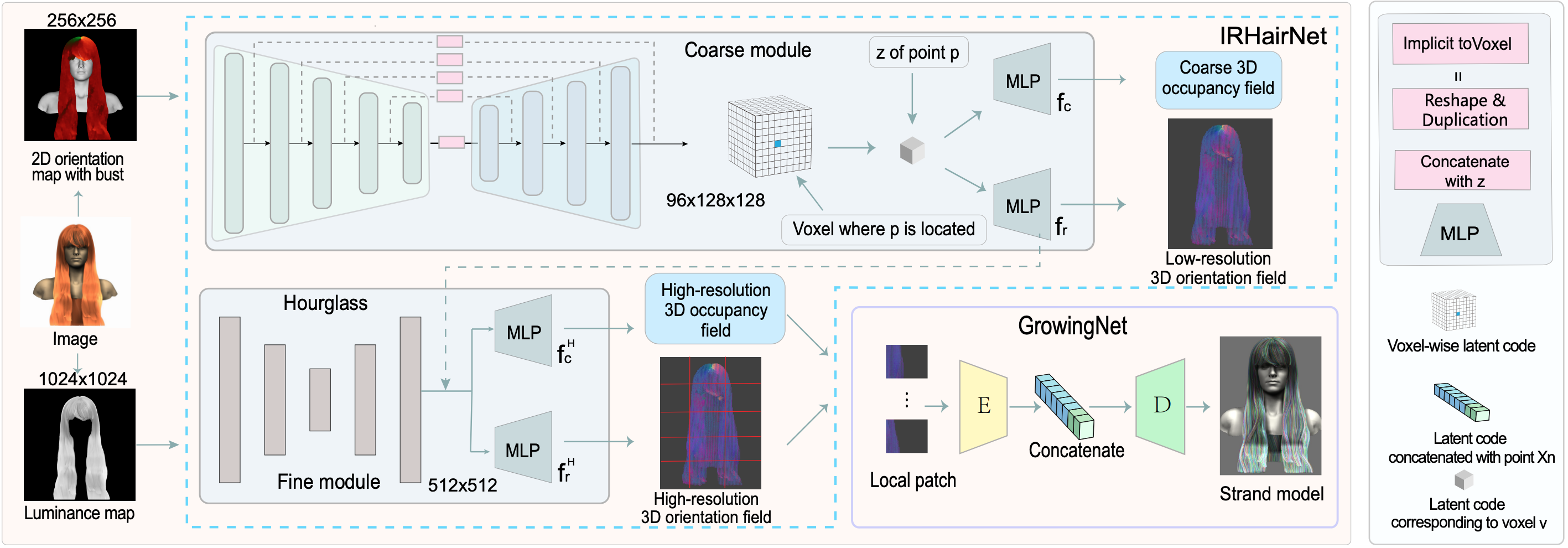
 NeuralHDHair: Automatic High-Fidelity Hair Modeling From a Single Image Using Implicit Neural RepresentationsKeyu Wu , Yifan Ye , Lingchen Yang, and 3 more authorsConference on Computer Vision and Pattern Recognition (CVPR) 2022.
NeuralHDHair: Automatic High-Fidelity Hair Modeling From a Single Image Using Implicit Neural RepresentationsKeyu Wu , Yifan Ye , Lingchen Yang, and 3 more authorsConference on Computer Vision and Pattern Recognition (CVPR) 2022.Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet (Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.
-
 iHairRecolorer: Deep Image-to-Video Hair Color TransferKeyu Wu , Lingchen Yang, Hongbo Fu , and 1 more authorScience China Information Sciences 2021.
iHairRecolorer: Deep Image-to-Video Hair Color TransferKeyu Wu , Lingchen Yang, Hongbo Fu , and 1 more authorScience China Information Sciences 2021.In this paper, we present iHairRecolorer, the first deep-learning based approach for example-based hair color transfer in videos. Given an input video and a reference image, our method automatically transfers the hair color in the reference image to the hair in the video while keeping other hair attributes (e.g., shape, structure, and illumination) untouched, producing vivid color-transferred dynamic hair in the video. Our method performs the color transfer purely in the image space, without any form of intermediate 3D hair reconstruction. The key enabler of our method is a carefully designed conditional generative model that explicitly disentangles various hair attributes into their corresponding sub-spaces, which are implemented as conditional modules integrated into a generator. We introduce a novel spatially and temporally normalized luminance map to represent the structure and illumination of the hair. Such a representation can largely ease the burden of the generator to synthesize temporally coherent vivid dynamic hairs in the video. We further introduce a cycle consistency loss to enforce the faithfulness of the generated results w.r.t. the reference. We demonstrate our system’s superiority in video hair color transfer by extensive experiments and comparisons to alternative methods.
-
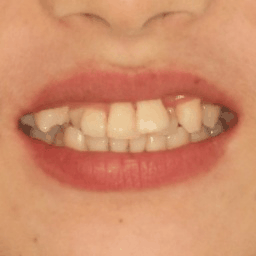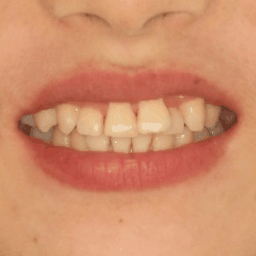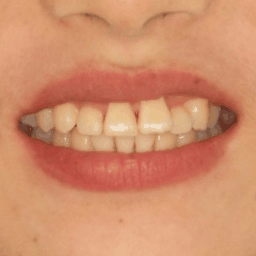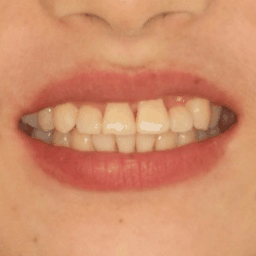 iOrthoPredictor: Model-Guided Deep Prediction of Teeth AlignmentLingchen Yang, Zefeng Shi , Yiqian Wu , and 4 more authorsACM Transactions on Graphics (SIGGRAPH ASIA) 2020.
iOrthoPredictor: Model-Guided Deep Prediction of Teeth AlignmentLingchen Yang, Zefeng Shi , Yiqian Wu , and 4 more authorsACM Transactions on Graphics (SIGGRAPH ASIA) 2020.In this paper, we present iOrthoPredictor, a novel system to visually predict teeth alignment in photographs. Our system takes a frontal face image of a patient with visible malpositioned teeth along with a corresponding 3D teeth model as input, and generates a facial image with aligned teeth, simulating a real orthodontic treatment effect. The key enabler of our method is an effective disentanglement of an explicit representation of the teeth geometry from the in-mouth appearance, where the accuracy of teeth geometry transformation is ensured by the 3D teeth model while the in-mouth appearance is modeled as a latent variable. The disentanglement enables us to achieve fine-scale geometry control over the alignment while retaining the original teeth appearance attributes and lighting conditions. The whole pipeline consists of three deep neural networks: a U-Net architecture to explicitly extract the 2D teeth silhouette maps representing the teeth geometry in the input photo, a novel multilayer perceptron (MLP) based network to predict the aligned 3D teeth model, and an encoder-decoder based generative model to synthesize the in-mouth appearance conditional on the original teeth appearance and the aligned teeth geometry. Extensive experimental results and a user study demonstrate that \sysname is effective in qualitatively predicting teeth alignment, and applicable to the orthodontic industry.
-
 Dynamic Hair Modeling From Monocular Videos Using Deep Neural NetworksLingchen Yang, Zefeng Shi , Youyi Zheng , and 1 more authorACM Transactions on Graphics (SIGGRAPH ASIA) 2019.
Dynamic Hair Modeling From Monocular Videos Using Deep Neural NetworksLingchen Yang, Zefeng Shi , Youyi Zheng , and 1 more authorACM Transactions on Graphics (SIGGRAPH ASIA) 2019.We introduce a deep-learning-based framework for modeling dynamic hairs from monocular videos, which could be captured by a commodity video camera or downloaded from Internet. The framework mainly consists of two network structures, i.e., HairSpatNet for inferring 3D spatial features of hair geometry from 2D image features, and HairTempNet for extracting temporal features of hair motions from video frames. The spatial features are represented as 3D occupancy fields depicting the hair shapes and 3D orientation fields indicating the hair strand directions. The temporal features are represented as bidirectional 3D warping fields, describing the forward and backward motions of hair strands cross adjacent frames. Both HairSpatNet and HairTempNet are trained with synthetic hair data. The spatial and temporal features predicted by the networks are subsequently used for growing hair stands with both spatial and temporal consistency. Experiments demonstrate that our method is capable of constructing high-quality dynamic hair models that resemble the input video as closely as those reconstructed by the state-of-the-art multi-view method, and compares favorably to previous single-view techniques.
-
 Controlling Stroke Size in Fast Style Transfer With Recurrent Convolutional Neural NetworkLingchen Yang, Lumin Yang , Mingbo Zhao , and 1 more authorComputer Graphics Forum (Pacific Graphics) 2018.
Controlling Stroke Size in Fast Style Transfer With Recurrent Convolutional Neural NetworkLingchen Yang, Lumin Yang , Mingbo Zhao , and 1 more authorComputer Graphics Forum (Pacific Graphics) 2018.Controlling stroke size in Fast Style Transfer remains a difficult task. So far, only a few attempts have been made towards it, andthey still exhibit several deficiencies regarding efficiency, flexibility, and diversity. In this paper, we aim to tackle these problemsand propose a recurrent convolutional neural subnetwork, which we callrecurrent stroke-pyramid, to control the stroke size inFast Style Transfer. Compared to the state-of-the-art methods, our method not only achieves competitive results with much fewerparameters but provides more flexibility and efficiency for generalizing to unseen larger stroke size and being able to producea wide range of stroke sizes with only one residual unit. We further embed therecurrent stroke-pyramidinto the Multi-Stylesand the Arbitrary-Style models, achieving both style and stroke-size control in an entirely feed-forward manner with two novelrun-time control strategies














